什么是哈希表呢?
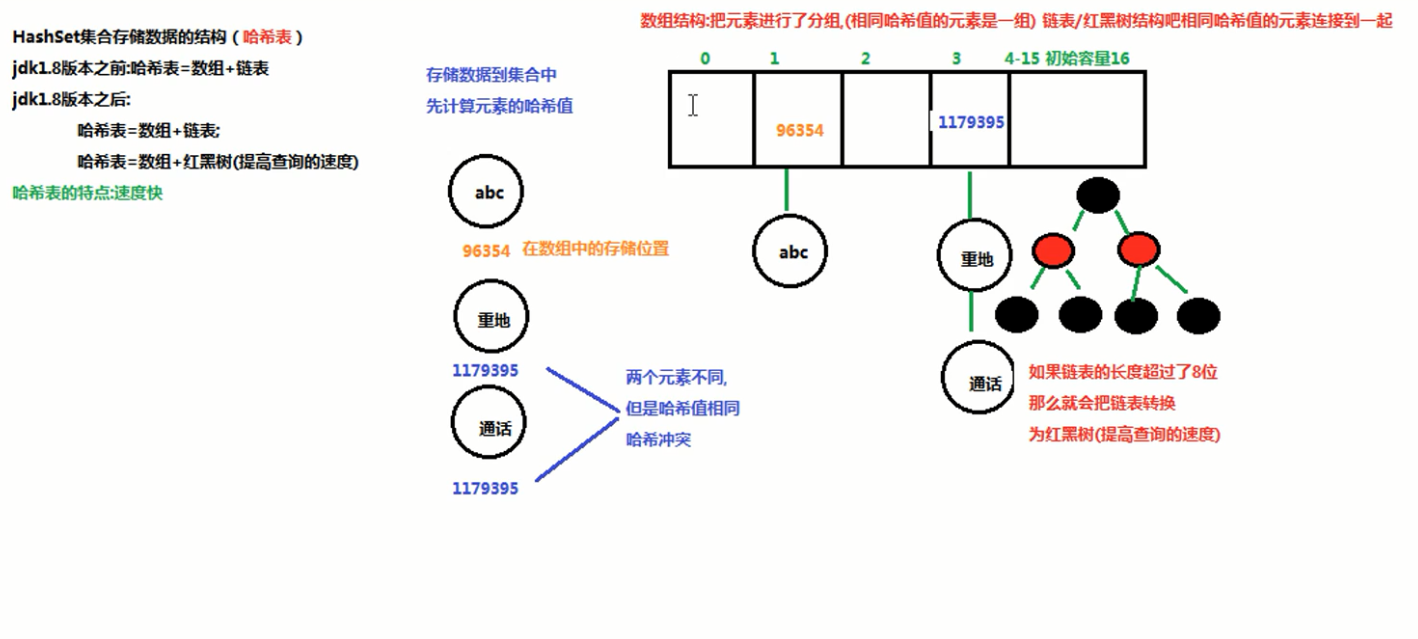
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的元素都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。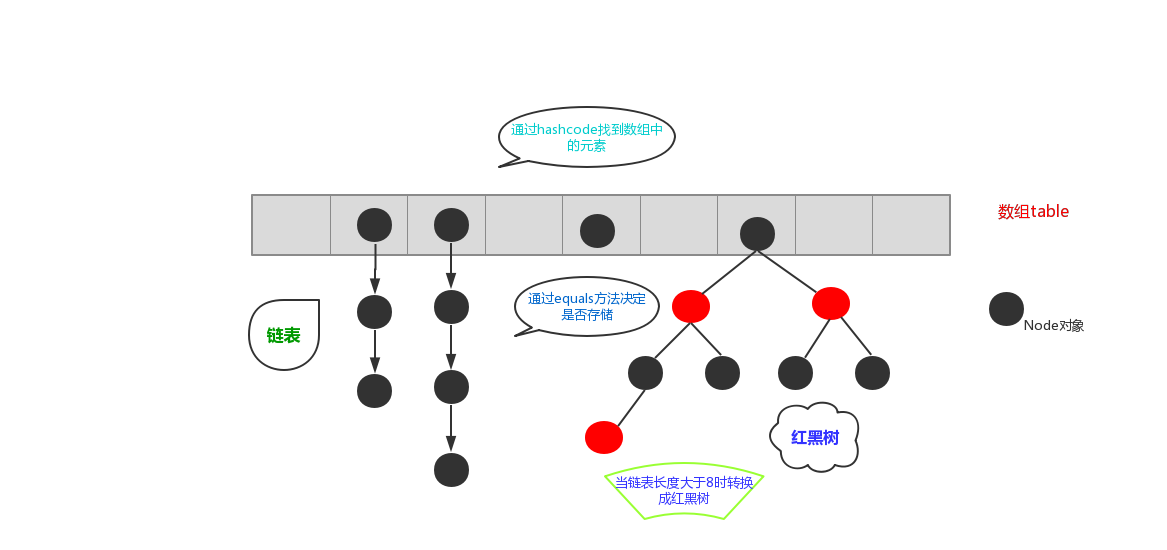
看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下:
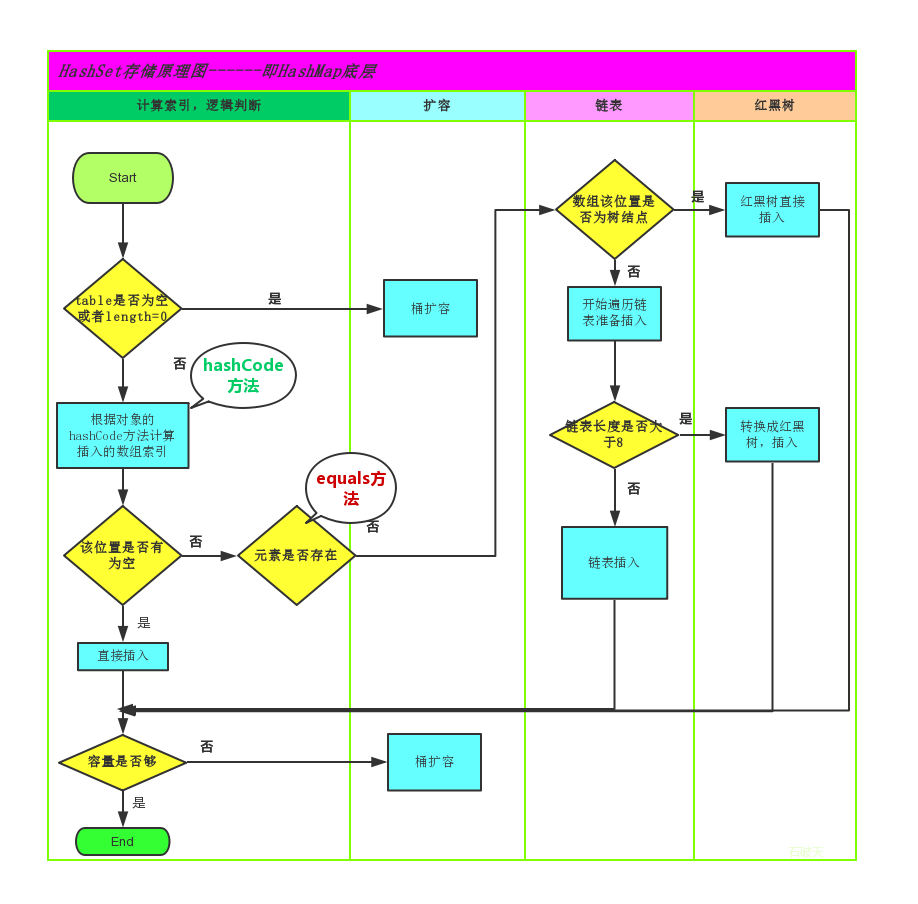
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| package com.itheima.demo03.hashCode;
public class Demo01HashCode {
public static void main(String[] args) {
Person p1 = new Person();
int h1 = p1.hashCode();
System.out.println(h1);
Person p2 = new Person();
int h2 = p2.hashCode();
System.out.println(h2);
System.out.println(p1);
System.out.println(p2);
System.out.println(p1==p2);
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println("重地".hashCode());
System.out.println("通话".hashCode());
}
}
|
1
2
3
4
5
6
7
8
9
10
| package com.itheima.demo03.hashCode;
public class Person extends Object{
@Override
public int hashCode() {
return 1;
}
}
|

